论文:https://arxiv.org/abs/1903.00621
Motivation
目标检测领域中物体尺寸一直是难以解决的问题,常见的解决方案就包括Feature Pyramid Network(FPN)。它利用多级的feature map去预测不同尺度的物体,其中高层特征带有高级语义特征和较大的感受野,适合检测大物体,浅层特征有着丰富的位置信息更具细节,适合检测小物体。 同时FPN逐步融合了浅层特征和高层特征,使得浅层也能获得高级语义信息,增强了表达能力,提高了检测性能。
在FPN框架中,会定义一系列的anchor,它们稠密地分布在各个feature map中。这些anchor会根据其不同的尺寸大小和不同的feature map联系起来,然后选择合适的feature map负责检测物体。在带有FPN的backbone中,高层的feature map分辨率高,得到的anchor数量多尺寸小,浅层的feature map分辨率低,得到的anchor数量少尺寸大,anchor的生成是根据feature map不同而定义的。在anchor match gt阶段,gt与anchor匹配,确定gt归属于哪些anchor,这个过程隐式的决定了gt会由哪层feature map负责预测。
但这样会带来两个问题:1)启发式的特征选择;2)基于重叠的anchor采样。如下图,60x60大小的车和50x50大小的车被分在了不同的feature map进行预测,而50x50大小和40x40大小的车被分在了同一个feature map中,这种方式是最优的吗?显然无法证明。
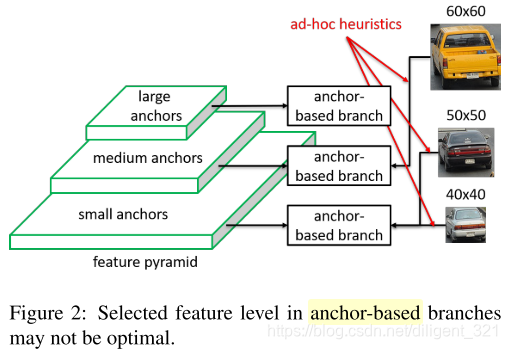
既然anchor box的分配和选择都不是最优的,那么就干脆舍弃anchor,让模型自动学习选择合适的feature做预测,本文就提出了FSAF模块,让每个instance自动的选择最合适的feature,在这个模块中,anchor box的大小不再决定选择哪些feature进行预测,也就是说anchor (instance) size成为了一个无关的变量,这也就是anchor-free的由来。因此,feature 选择的依据有原来的instance size变成了instance content,实现了模型自动化学习选择feature。
Feature Selective Anchor-Free Module
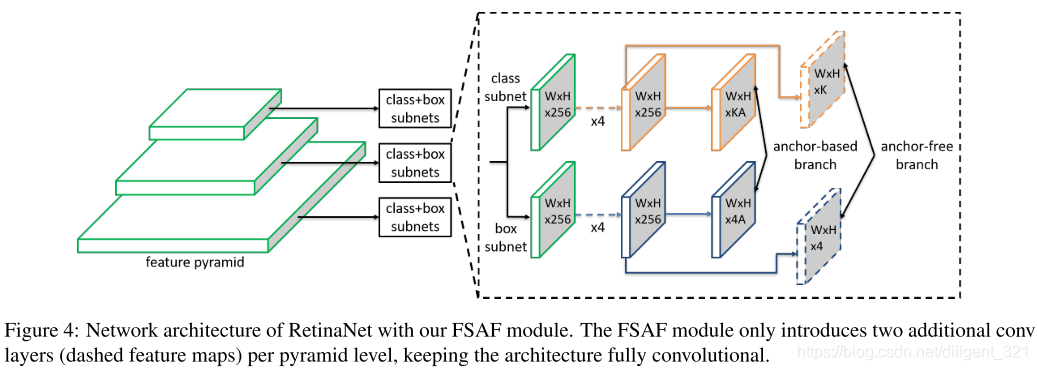
Network Architecture(怎么设计anchor-free分支网络结构)
- feature pyramid每层仅引入两个额外的卷积层,分别负责anchor-free的预测与回归。
Ground-truth and Loss Given(怎么为anchor-free分支产生监督信号)
几个概念:
- gt box类别:k
- gt box坐标:b=[x, y, w, h]
- gt box在第l个特征层上的投影$b_p^l=[x_p^l, y_p^l, w_p^l, h_p^l]$
- effective box:$b_e^l=[x_e^l, y_e^l, w_e^l, h_e^l]$,表示投影的一部分,缩放比例系数$\epsilon_e=0.2$(对应图上白色部分)
- ignoring box:$b_i^l=[x_i^l, y_i^l, w_i^l, h_i^l]$,表示投影的一部分,缩放比例系数$\epsilon_i=0.5$(对应图上灰色部分)
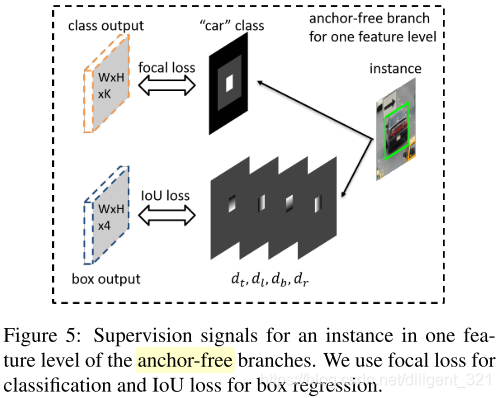
- 分类输出:输出一个WxHxK大小的feature map,K表示物体类别数,那么在坐标为(i,j)的点上是一个长度为K的向量,表示属于每个类别的概率。分支对应的gt是图中白色区域内值为1,表示正样本,黑色区域内值为0,表示负样本,灰色区域是忽略区域
不回传梯度。分支采用Focal Loss,整个classification loss是非忽略区域的focal loss之和,然后除以有效区域内像素个数之和来正则化一下。 - 回归输出:输出一个WxHx4大小的feature map,那么在坐标为(i,j)的点上是一个长度为4的向量,分别表示4个偏移量。假设一个instance,其在feature level为l对应的有效区域$b_e^l$内的每个值。假设坐标为(i,j),长度为4的向量$x_{i, j}^l$表示这个instance的上、左、下、右4边界和(i,j)的距离,然后$x_{i, j}^l/S$(S是个
归一化常数)作为最后输出结果。分支采用IoU Loss,整个regression loss是一张图片中每个有效区域的IoI Loss的均值。
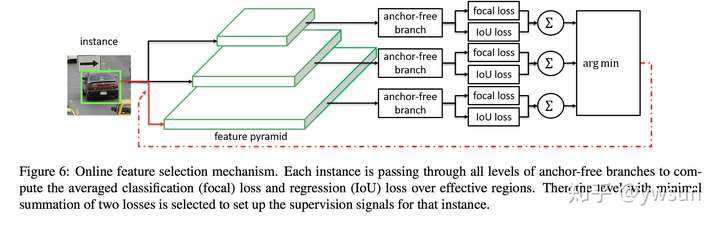
Online Feature Selection(自动选择最佳feature)
选择过程:
- 每层feature level都计算instance的分类和回归损失(focal loss,IoU loss)
$$L_{FL}^I(l) = \frac{1}{N(b_e^l)}\sum_{i, j\subset b_e^lt}FL(l, i, j)$$
$$L_{IoU}^I(l) = \frac{1}{N(b_e^l)}\sum_{i, j\subset b_e^lt}IoU
(l, i, j)$$ - 从上述结果中选择loss最小的那一层做反向传播
Joint Inference and Training
- FSAF可单独作为一个模块预测也可以和原来anchor-based分支同时并存,当两者都存在的时候,两个分支的输出结果merge再经过NMS得到最终结果;
- 训练时采用multi-task loss,$L = L^{ab} + \lambda (L_{cls}^{af}+L_{reg}^{af})$
实验部分
作者在ablation study部分分析了anchor-free的必要性,online feature selection的重要性,以及选择的feature level是不是最优的。同时还指出FSAF非常robust和efficient,在多种backbone条件下,都有稳定的涨点。在ResNext-101中,FSAF超过anchor-based1.2个点,同时快了68ms,在AB+FSAF情况下,超过RetinaNet1.8个点,只慢了6ms,效果也是非常显著的。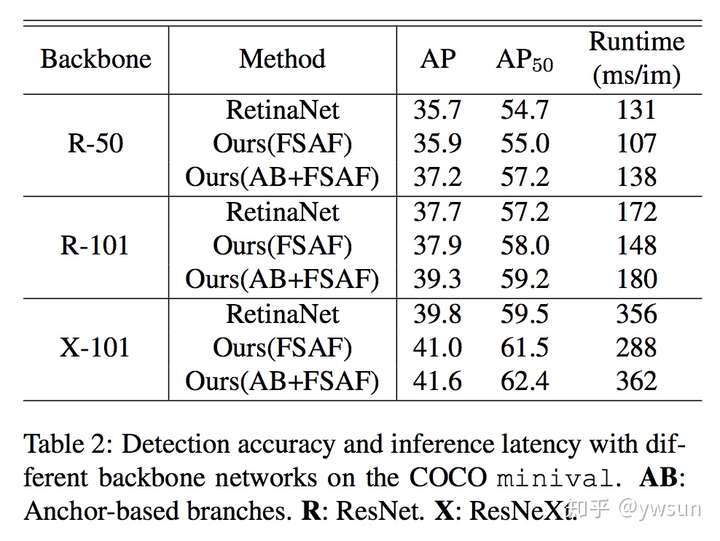
总结
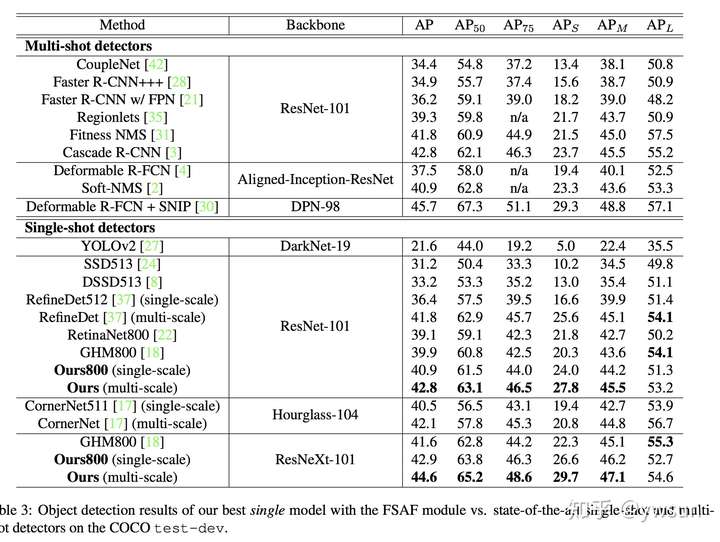
本文提出的FSAF模块有效缓解了物体尺寸问题,但从实验结果上来看,单独的FSAF模块并没有很大的提升,与anchor-based分支结合之后起到了互补的作用。
effect box和ignoring box的设计起了什么作用? 是为了更加有效选择那些IoU大的bbox?